
The phrase ‘Artificial Intelligence’, sweetly abbreviated as ’AI’ when put in front of a product, raises the expectations from a product beyond limits.
During the early pre-launch surveys with our clients on our AI-EnglishPro, we knew that our clients expected magic, and we had to provide the magic. Obviously, no rabbits were getting conjured from black hats but surely there was a problem to be solved: a reasonably accurate score of a candidate’s English Proficiency within reasonable time as a candidate speaks, writes, reads, and listens.
The other challenge was that our test, with an ability to automatically evaluate a candidate’s proficiency, would be compared against other manual variants of it. Unlike in some cases, wherein the prefix of AI is used as a marketing gimmick, we genuinely wanted to increase the trust of our Hiring Managers, Recruiters, Learning & Development Leaders, and other stakeholders in AI. We also wanted to ensure that AI actually helps them cut down their hiring or upskilling assessment time.
We started breaking the of a mammoth task at hand. While one team of experts started deep-diving on CEFR Compliance, another worked on the content of the initial variation of the test. The product team worked on the UX and candidate experience; and we, the Engineering team, started brainstorming the AI techniques, Reporting Engine, APIs, and the overall Integration and Architecture.
Being an English Proficiency Test, surely the major department of AI/ML we were to use was the NLP (Natural Language Processing). However, that didn’t cut down on the brainstorming efforts.
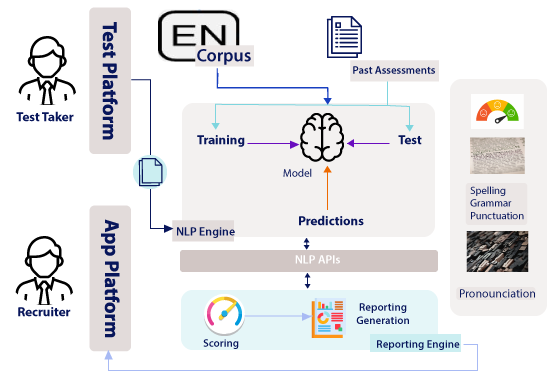
The initial mornings started with alternatives. The questions that rose were should we go with models of our own, should we use services of Cognitive Service Providers like Microsoft. And if we go with our own models, where do we build, train, and test the models.
Furthermore, we had multiple enabling skills against which we were planning to assess the candidates. For example, we started with Oral Fluency, Vocabulary, Grammar and Spelling, and Sentiment Analysis for speaking. For writing, we started with Vocabulary, Grammar and Spelling, Sentiment Analysis, and Writing Fluency with road-map items of Pronunciation Check and Context Check Analysis.
We decided to do a mix and match for our beta version. The plan was to use our own models for few evaluation points; and for a few, check with third party libraries or pre-built cognitive services.
We knew that the technology stack, the models, the architecture, etc. would keep evolving. Hence, we decided to start with very basic models in our initial beta version, gathering data on the beta version of the tests, and using that data to train our models for subsequent phases.
So we started with VADER (from the NLTK library) for Sentiment Analysis, a third party library for grammar and spelling check, heavy pre-processing and analysis using NLTK and spaCy, the most popular NLP libraries for other evaluation points. The initial check for vocabulary was through a NLP concept called Named Entity Recognition, only to later realize that it definitely doesn’t come close on its own.
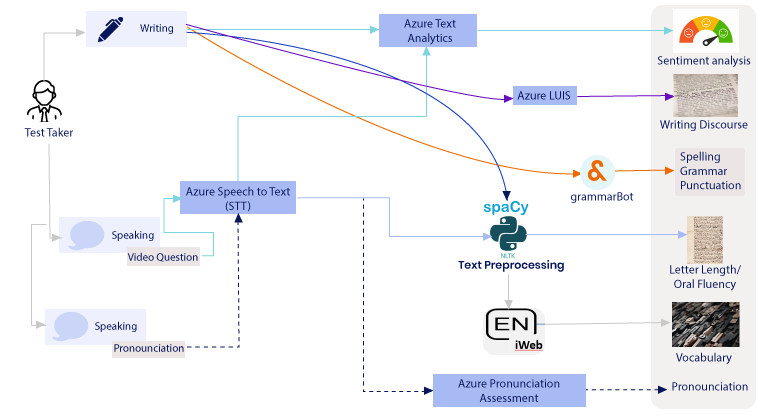
This basic selection of models or third-party libraries helped with creating a very initial framework of our NLP Engine, integrate it with our test platform as the upstream and reporting Engine as the downstream, containerize, deploy on our Microsoft Azure subscription, and initiate the beta version of the test to some of our friendly clients.
This initial beta version proved to be the key to our success. It not only helped with validating our end-to-end integration flow, test our exception and error handling, test our architecture, test the look and feel of the reports, candidate experience, etc. but it also helped us correct our assumptions on the data. Post the initials assessments, we went back to the whiteboard for few weeks.
The outcomes were many, the four prominent ones being:
- We were able to replace VADER with our own model based on BERT and Binary classifier
- We successfully replaced the NER based scoring for vocabulary with frequency distribution analysis of one of the largest corpus
- We attempted to replace the third-party library without own model again based on BERT
- And finally, multi-label classifiers were tested on GEC
On the architecture front, there were heavy changes as well. For example, the underlying messaging medium was changed, container configuration, changes to the base docker images, etc. The UX changed, the content of the tests changed a bit, and a lot more changes were done on candidate experience.
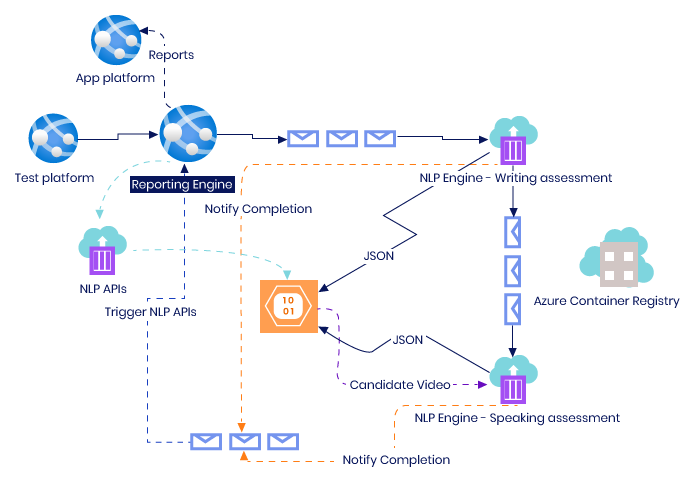
Coming back to the AI, we started thinking more and more on the ML Ops, dataset curation, hyper parameters tuning, heavy training, validation and testing of our models, etc.
However, one amazing thing that happened during these efforts was that we got connected with the Microsoft’s specialists and engineering team. Detailed brain-storming with Microsoft engineering team and architects helped us change our direction slightly. We started looking at Microsoft Azure Machine Learning Services to build, train, and test our models in order to help with ML Ops mainly. Parallelly, we also started looking at Microsoft Cognitive Services offerings. The Microsoft team, by this time, well understood our use case; and because of our frequent calls followed by POCs and tests, we were able to close down the use of Azure Cognitive Services like Text Analytics, Speech Services, Custom Text, Azure Video Indexer, and other offerings for the phase two of the product.
We were then on a mix of our own models, third party libraries, NLTK, spaCy, and Azure Cognitive services. It seemed perfect.
We rolled out the phase two changes to some clients of ours. Though the results were great, there was a lot of calibration required. Our main clients for AI-EnglishPro are based in the USA and India, and hence we had to recalibrate keeping both audiences in mind. This exercise took few weeks, each of us were taking multiple tests ourselves, regeneration of reports post each change in logic and comparing if the results of the logic are acceptable, taking client feedbacks, going over candidate feedbacks from the tests, etc.
Fast forwarding, our improved version of the test is now actually helping some of our clients assess their candidates on Business English, and the efforts seem to have paid off based on our client feedbacks. However, we are not stopping here for sure. We are constantly learning and improving.
We assess the data and how our models and Azure Cognitive Services religiously on a daily basis, and any discrepancies are fixed in our models or sent to the Microsoft Engineering team for their inputs.
Moving to the roadmap, one of the key question our clients ask is if they can customize the test. We understand that our clients have various use cases, for example, checking the English Proficiency in a support role, in a back office role, in a management role, and hundreds of other use cases. Due to the requirement of data set and training and testing of the models for each of this use case, we surely cannot open hundreds of these use cases; however, we are in the process of opening some of these key use cases.
We also have been asked by our clients about our pronunciation check. However, AI-EnglishPro is CEFR compliant and, as per the changes in the Phonological Control aspect of CEFR 2018, which stresses on intelligibility rather than ascent and pronunciation, we have decided to make another product that checks pronunciation of a candidate against a reference text.
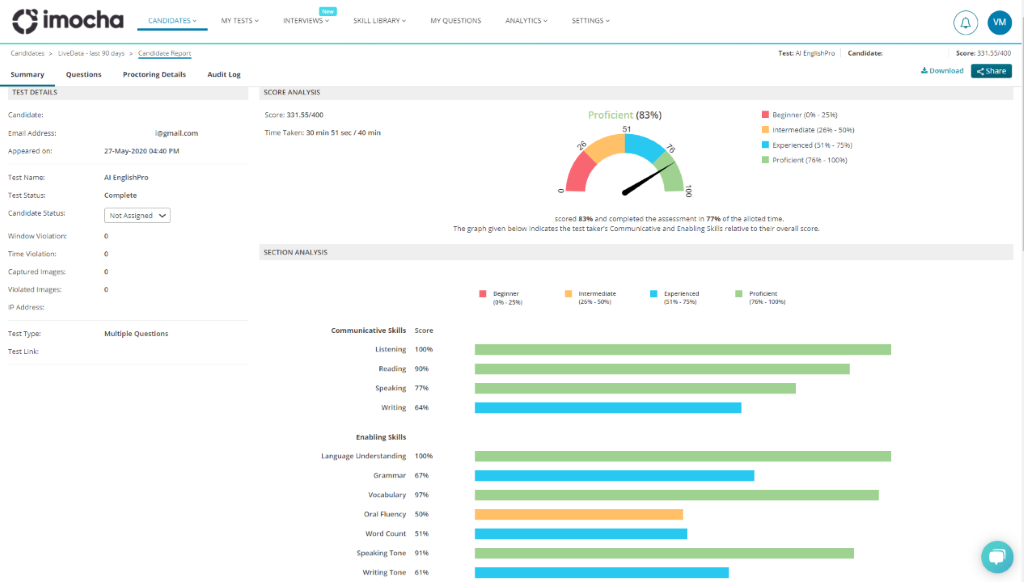
The results of this undertaking have been overwhelming to say the least; we have completed the initial 1000 assessments for a client of ours in Edu-Tech and the results are great, but a lot needs to be done still.
We love to see our clients happy and we love to see them astonished by the magic. We haven’t been able to bring out a rabbit through AI; however, I believe we surely have been able to magically bring out a right unbiased assessment of proficiency of their candidates.
You can learn more about AI-EnglishPro here.
